
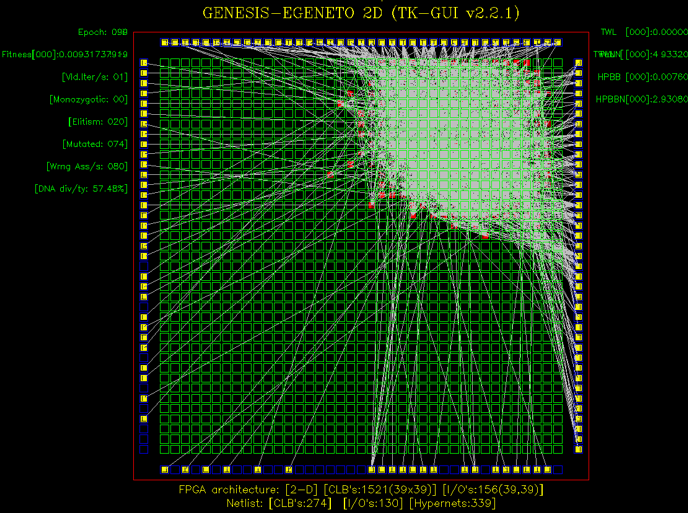
Physical Design Frameworks
Netlist partitioning, placement and routing are though as the most time-consuming processes in physical design flows, while they dominate performance (i.e. frequency and power) metrics. We have proven experience in CAD algorithms and tools for supporting physical design for reconfigurable and architectures (FPGAs) and digital platforms. Our group has experience with industrial framework for this purpose, including among others Xilinx Vivado and Altera Quartus.
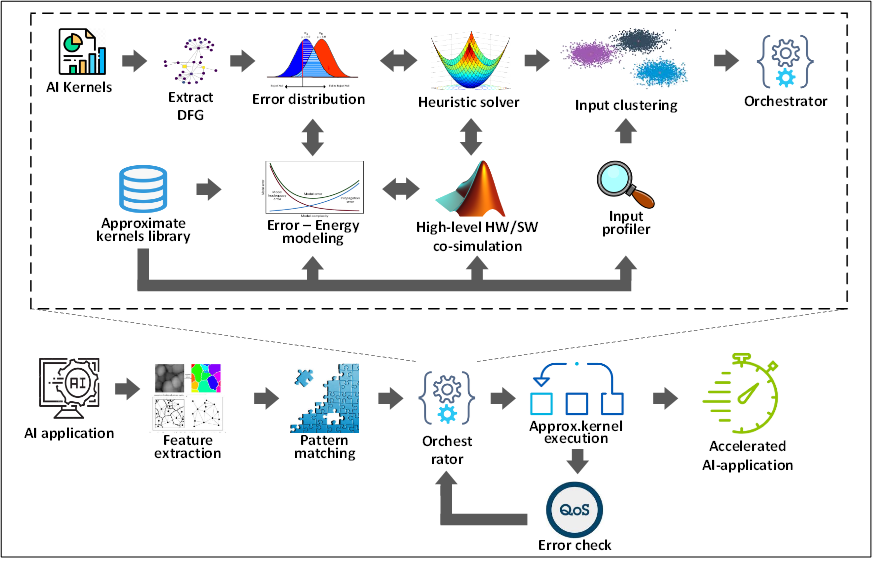
Workload-aware Approximate Kernels
Leveraging the inherent error resilience of a large number of application domains, approximate computing is established as an efficient design alternative to improve their energy profile. The proposed solution relies on a repository with customizable templates of approximate kernels per application’s IP that are configured (fine-tuned) at run-time depending on application’s workload. By trading-off accuracy with energy consumption it is feasible to achieve real-time analysis for large data volumes. The configuration task is orchestrated by a run-time execution controller which monitors application’s workload in order to select the most suitable approximation kernel.
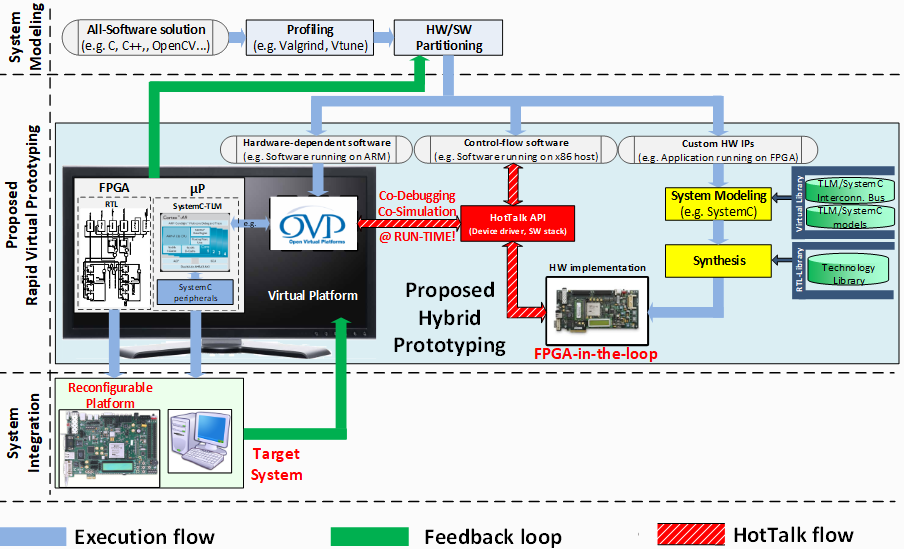
Rapid Prototyping
Heterogeneous architectures featuring multiple hardware accelerators have been proposed as a promising solution for meeting the ever-increasing performance and power requirements of embedded and High-Performance Computing systems. However, the existence of numerous design parameters may result in different architectural schemes and thus in extra design effort. Our group has experience on Virtual Prototyping solutions, such as Hardware-in-the-Loop (HiL), in order to provide a co-simulation environment for designing in an efficient manner data-parallel many-accelerator systems. State-of-the-art devices are employed for this purpose (such as Xilinx Alveo, Ultrascale, Zynq, Pynq, as well as Altera/Intel Stratix-V boards).
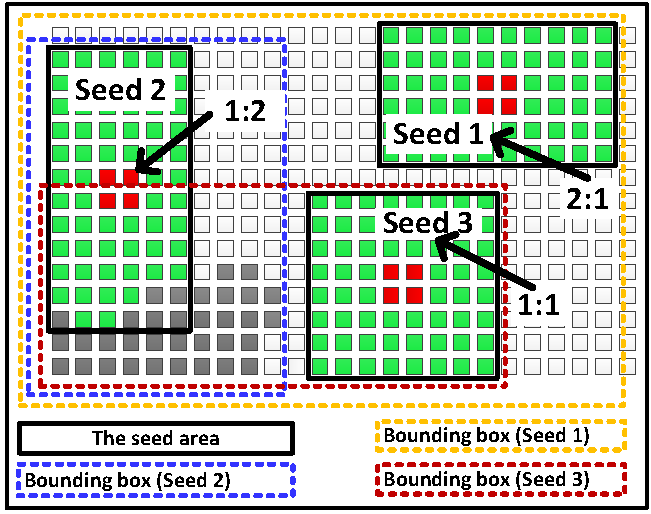
Just-In-Time (JIT) Compilation
The execution runtime usually is a headache for designers performing application mapping onto reconfigurable architectures. Techniques that accelerate core CAD algorithms can bring about important changes in product design times for these applications, whereas many designers may be willing to trade off some quality of the solution for an improved runtime of the CAD tools. This software-supported framework targets to provide fast application implementation onto reconfigurable architectures with a Just-In-Time (JIT) compilation framework. Apart from reducing compilation times, the proposed solution addresses also the challenge related to device fragmentation, as it has considerable impact to the performance of upcoming applications.This task becomes far more savage for high-density FPGAs since over the time, as a partially reconfigurable device loads and unloads configurations, the hardware resources are likely to become fragmented.
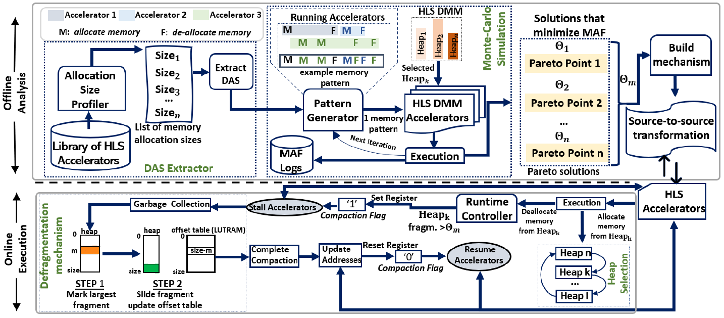
Dynamic Memory Management (DMM) for Xilinx High-Level Synthesis (HLS) Framework
Many-Accelerator (MA) systems have been introduced as a promising architectural paradigm that can boost performance and improve power of general-purpose computing platforms. This framework focuses on the problem of resource under-utilization, i.e. Dark Silicon, in FPGA-based MA platforms. Recognizing that static memory allocation (the de-facto mechanism supported by modern design techniques and synthesis tools) forms the main source of memory-induced Dark Silicon, the DMM4FPGA tool extends conventional High Level Synthesis (Xilinx Vivado HLS) with dynamic memory management (DMM) features, enabling accelerators to dynamically adapt their allocated memory to the runtime memory requirements, thus maximizing the overall accelerator count through effective sharing of FPGA’s memories resources.
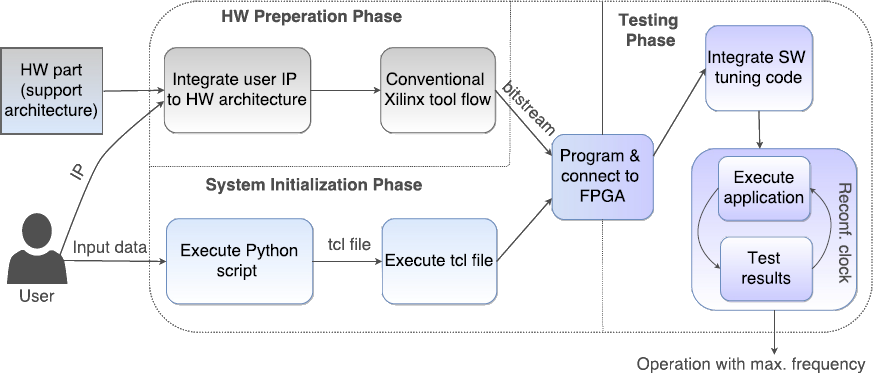
Variability-aware Application Mapping onto FPGAs
The toolset focuses on the variability effect in FPGAs and the possibility to boost the performance of each device at run-time, after fabrication, based on the individual characteristics of this device. For this purpose we develop a sensing infrastructure involving a wide network of customized ring oscillators to measure intra-chip and inter-chip variability for FPGA devices. Then, there is a closed-loop framework based on dynamic reconfiguration of clock tiles, I/O data sniffing, HW/SW communication, and verification with test vectors, to dynamically increase the operating frequency in Zynq while preserving its correctness.